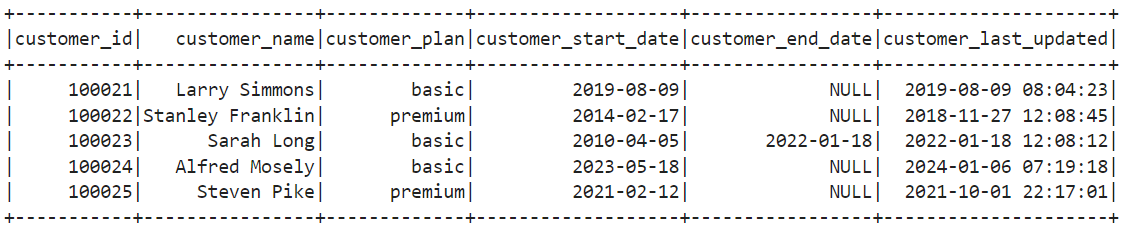
It is often a surprise to data engineers that objects stored in HDFS, S3, and GCS are immutable. The next question is "if objects are immutable, how do we handle changes to data?". The guidance is to simply upload a new version of the object either replacing the existing or creating a newer version. What we call a destructive update.
As you know that answer sounds good on the surface but does not meet requirements of enterprises which have need to have a record of changes. Some providers offer versioning or other new tools/services to accomplish non-destructive updates, but we find that they work only on small data, but we work with big data and these shiny new services usually fall short either in performance or cost.
So the issues is that we need non-destructive updates, SCD (Slowly Changing Dimensions) for those coming from an RDBMS background. We need to know the current state of the data (as-is) and the historical state of the data at a point-in-time (as-was).
There are several ways to update a dataset these days. A few open-source and commercial products are available to overcome the immutable file problem. Apache Hudi, Delta Lake, Snowflake, Iceberg, etc. seek to provide the update capability. All these products work well and can be used in the upsert process; however, it is just as important to know what changed and when it changed as it is to change the data.
We have found over the years that the following process is the simplest and best for cases that require CDC. So let's look at and discuss how we do this. Since we need to have know the as-was state of data, we'll need to capture the updates, changes, and new records added to the system. An upsert or destructive update would not meet the requirement.
The process is quite simple. We read the current customer data and perform a full outer join with the incoming delta data.
Terminology:customer_full_join_df = customers \
.join(delta_customers, customers.customer_id == delta_customers.delta_customer_id, "fullouter")
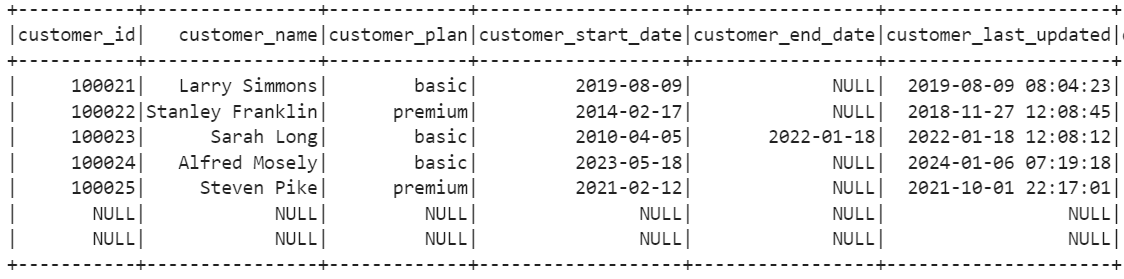

new = customer_full_join_df \
.filter("customer_id is null") \
.select('delta_customer_id', \
'delta_customer_name', \
'delta_customer_plan', \
'delta_customer_start_date', \
'delta_customer_end_date', \
'delta_customer_last_updated' \
)
If the both the customers_id and delta_customer_id are NOT null and the current customer end date field is null indicating it is an active customer and the delta or incoming record has a date in the customer end date field then the cusomter is deleted. We see that Sarah Long has closed her account and is deleted from the system.


updated = customer_full_join_df \
.filter("delta_customer_id != 'NULL' and customer_id != 'NULL' \
and (delta_customer_name != customer_name \
or delta_customer_plan != customer_plan \
or delta_customer_start_date != customer_start_date)")


unchanged = customer_full_join_df \
.filter("delta_customer_id != 'NULL' and customer_id != 'NULL' \
and delta_customer_name == customer_name \
and delta_customer_plan == customer_plan \
and delta_customer_end_date == customer_end_date \
and delta_customer_start_date == customer_start_date")
new.withColumnRenamed('delta_customer_id', 'customer_id') \
.withColumnRenamed('delta_customer_name', 'customer_name') \
.withColumnRenamed('delta_customer_plan', 'customer_plan') \
.withColumnRenamed('delta_customer_start_date', 'customer_start_date') \
.withColumnRenamed('delta_customer_end_date', 'customer_end_date') \
.withColumnRenamed('delta_customer_last_updated', 'customer_last_updated') \
.unionAll(updated.drop(col('customer_id'),
col('customer_name'),
col('customer_plan'),
col('customer_start_date'),
col('customer_end_date'),
col('customer_last_updated')) \
.withColumnRenamed('delta_customer_id', 'customer_id') \
.withColumnRenamed('delta_customer_name', 'customer_name') \
.withColumnRenamed('delta_customer_plan', 'customer_plan') \
.withColumnRenamed('delta_customer_start_date', 'customer_start_date') \
.withColumnRenamed('delta_customer_end_date', 'customer_end_date') \
.withColumnRenamed('delta_customer_last_updated', 'customer_last_updated')) \
.unionAll(unchanged.drop(col('delta_customer_id'),
col('delta_customer_name'),
col('delta_customer_plan'),
col('delta_customer_start_date'),
col('delta_customer_end_date'),
col('delta_customer_last_updated'))) \
.unionAll(deleted.select('customer_id',
'customer_name',
'customer_plan',
'customer_start_date',
current_date().alias('customer_end_date'),
current_timestamp().alias('customer_last_updated')))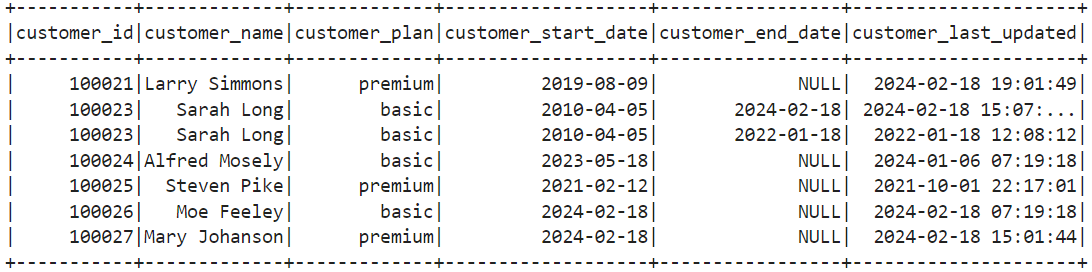
Now we have 4 datasets and a clear understanding of the delta records' effect on the current dataset. We can apply business rules to each dataset. This process gives us more control and insight into what has changed, when, and how.
If we see any deleted records, we want to apply the deletes and send an email or other business flow. We may wish to end processing if the number of deleted or changed records is too high. This type of analysis is complex when you are applying upserts in bulk.