I have been lucky enough to start working with Hadoop 12 years ago when it first hit the scene. I was just in the right place at the right time and participates in architecting and engineering some of the largest Hadoop cluster in the US. I have built multi-tenant hadoop clusters in the banking, telecommunications, utility and retail sectors. For the most part I have used the same architecture and thought I would share it with you so that perhaps you can learn something or pickup some tips and tricks.
A company has a very large RDBMS-based architecture containing thousands of databases, hundreds of servers and many users and applications. The cost of licensing has grown exponentially, and it is difficult if not impossible to serve all the new analytics use cases which include machine learning. Data scientists are not able to run large machine learning jobs on big data due to the amount of resources required, there have been outages due to their attempts in the past. The cost of licenses, continually adding servers to the database cluster and the inability to provide a platform for deep learning leads the company to seek a true big data solution and decides to begin a multi-year strategy to build and migrate to a Hadoop cluster.
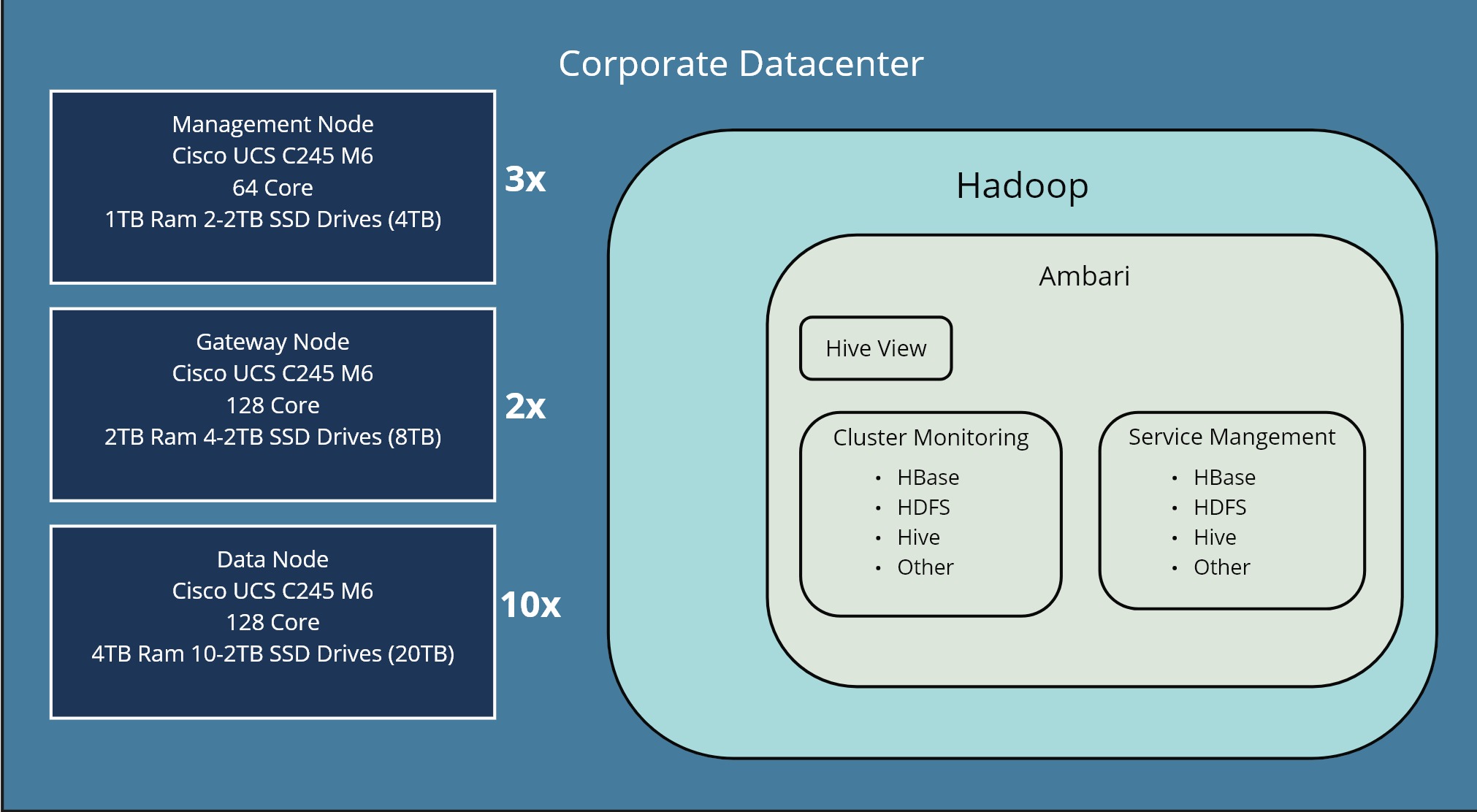
The Hadoop cluster had 10 data-nodes, each with 128 cores, 8TB ram and 10-2TB SSD drives. So the total size of the cluster was very large, 1280 cores, 40TB ram, 20TB (4PB) of disk storage. So this is considers a large hadoop cluster.
The Yarn configuration was 1 core and 2GB yarn containers, so we could support 1280 containers.
We had approx 30 different business units that were called tenants on the platform. Each tenant was provided a yarn queue with quotes set based on the funding and requests from the business unit. We also had a generic queue for adhoc and admin workloads that didn't fit into a business unit. This adhoc queue could use the entire cluster but was the lowest priority so any workloads that came in would preempt the adhoc workload
Each queue is allocated a minimum resource allocation of 20% of cluster resources with a maximum of 100% of cluster resources when the cluster is not in use.
Preemption is enabled on all queues so workloads will be interrupted if any queue does not have 20% of cluster resources available.
You can also use this to provide a larger portion of the cluster to a business unit that provides more funding than another.
| Queue Name | Minimum Resources | Maximum Resources | Preempt-able |
|---|---|---|---|
| finance | 10% | 100% | True |
| advertising | 20% | 100% | True |
| human resources | 10% | 100% | True |
| adhoc | 20% | 100% | True |
| administration | 20% | 100% | False |
Typically you will ask new tenant to purchase a node to contribute to the cluster. The new tenant can immediately start using the cluster as it will take some time to procure hardware but as the next tenant joins contributing a node it will benefit all tenants.
You'll want to talk with the new tenant to understand their workloads. The new tenant could be all adhoc query and does not plan on executing any scheduled jobs. This tenant would need its own queue as the adhoc queue is more for single user exploration of the data.
The administration queue if for maintenance jobs, usage reports, etc. that don't really fit into a queue. It is also fully preempt-able as the jobs are generally low priority.
After you understand the workload you can create the resources needed by the business unit.
| Service | Resource | Description |
|---|---|---|
| HDFS | HDFS Directories for application data and code |
|
| Gateway Node | Linux File System for application data and code |
|
| Apache Hive | Business unit databases |
|
| Active Directory | Service account to run applications with Kerberos |
|
Gateway nodes are the entrypoint to the cluster. Hadoop commands are available and can be executed from the edge node. Enterprise scheduling software like Autosys, Tidal, etc. will be installed on the Gateway nodes for job execution.